Bolting AI onto a broken process doesn’t fix the process. It automates the dysfunction.
This is the uncomfortable truth sitting underneath most enterprise AI initiatives right now. The pressure to ship something with AI in it has never been higher. The discipline required to make that something reliable, secure, and governable in production has never been more scarce.
The benchmark trap is one of the most expensive lessons in enterprise AI today. A model performs excellently across every evaluation in the lab — then hits a wall the moment it touches a live fintech workflow, a legacy data layer, or a multi-team integration point. That’s not a model failure. It’s an environment failure. Production readiness means auditing everything around the AI: data pipelines, access controls, fallback logic, human-in-the-loop checkpoints. The model is often the least broken piece in the room.
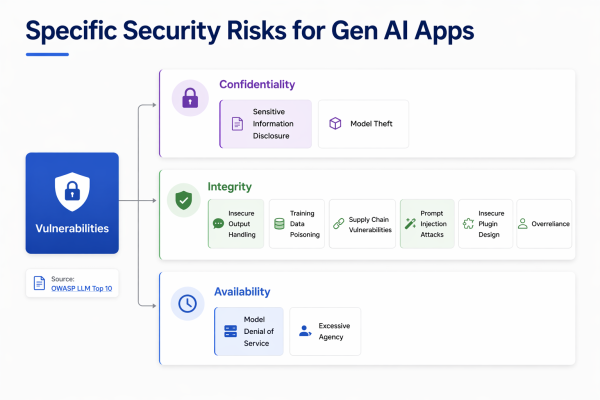
The OWASP LLM Top 10 makes the risk surface impossible to ignore. GenAI applications carry vulnerabilities across three dimensions simultaneously — confidentiality, integrity, and availability. Sensitive data exposure and model theft at the data layer. Prompt injection, training data poisoning, and insecure output handling at the model layer. Denial of service and excessive agency at the operations layer. Most teams are prepared for none of these at deployment time.
McDonald’s learned this publicly. Their AI chatbot, in production, was found accessing external AI systems in ways that were never designed or governed — a textbook case of Excessive Agency and insufficient output monitoring. If it can happen at that scale and with those resources, it can happen anywhere.
So what does a production-ready AI system actually require?
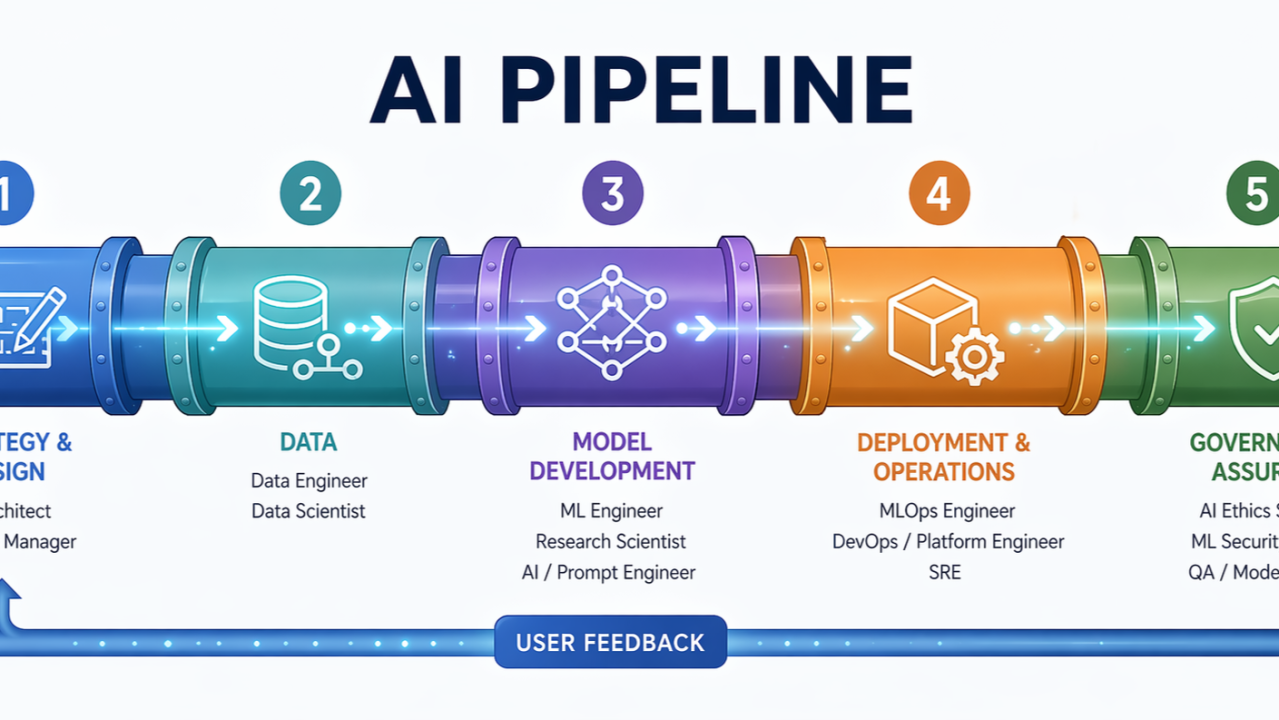
An AI pipeline is the end-to-end flow that takes raw data and turns it into a deployed, monitored system delivering consistent value. It is not a single engineer’s responsibility. It is not a one-time build. It is a living system with distinct layers, each with its own specialists, its own failure modes, and its own contribution to whether the whole thing holds together under real-world pressure.
Getting a model to perform well in a notebook is a solved problem. Getting that same model to perform reliably inside a live enterprise environment — with real data, real users, real compliance requirements, and real consequences when it goes wrong — is an entirely different discipline. That discipline requires a pipeline of specialised roles working in concert.
Here is what that pipeline actually looks like.
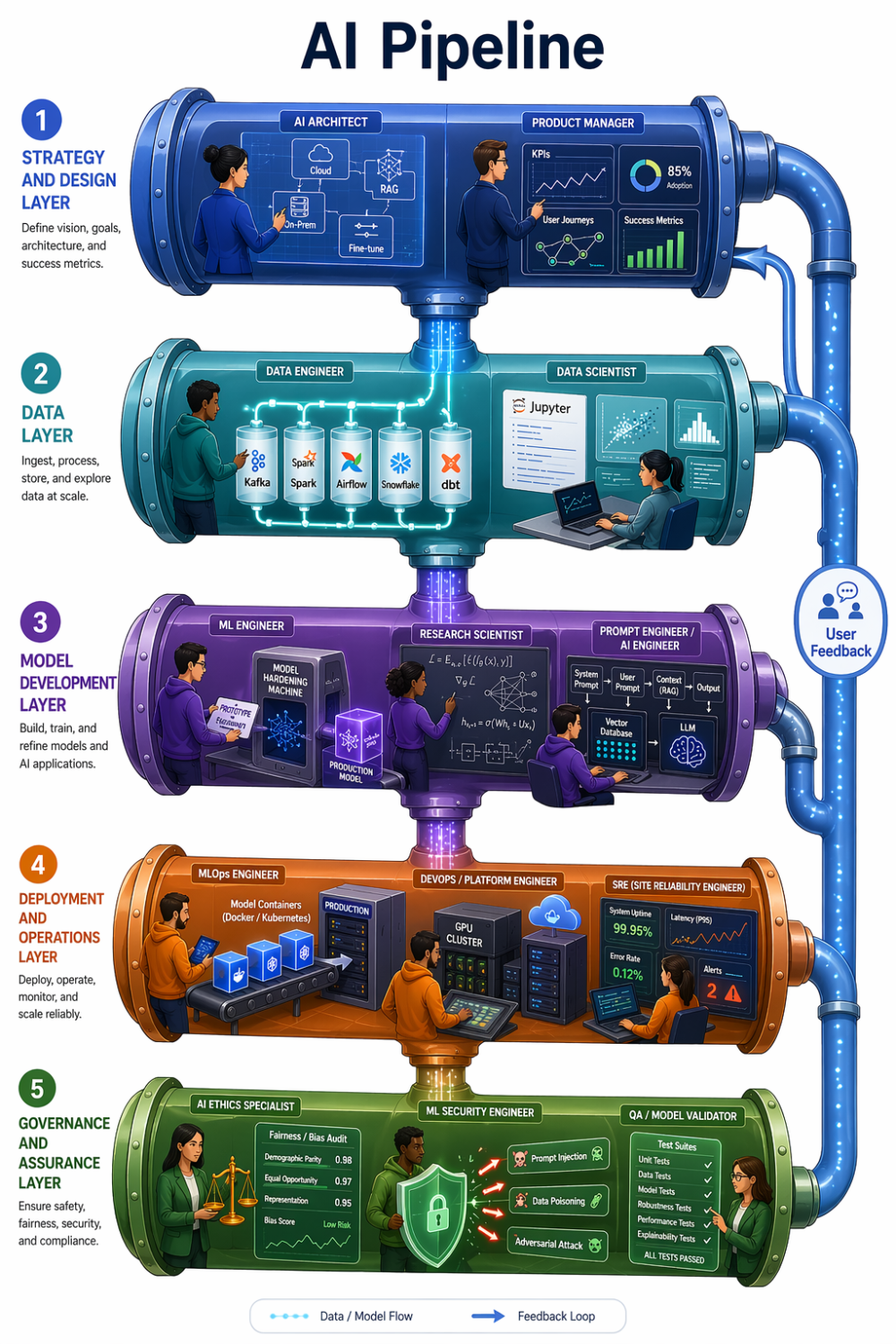
Layer 1 — Strategy and Design
Before a single line of code is written, an AI Architect translates the business problem into a technical blueprint. This is where the critical decisions happen: build vs. buy, fine-tuning vs. RAG vs. prompting, cloud vs. on-prem, which integration points with existing systems. The AI/ML Product Manager defines what success looks like and what the user actually needs.
When this layer is weak, teams build the right technology for the wrong problem — or the right problem with the wrong architecture.
Layer 2 — Data
Data Engineers build the plumbing: ingestion pipelines, transformations, and loading into warehouses, lakes, or feature stores. Tools like Airflow, Kafka, dbt, and Snowflake are the backbone here. Data Scientists then explore what the data actually contains — testing hypotheses, engineering features, and building the first proof-of-concept.
Without a strong data layer, everything downstream starves. A model is only as good as what feeds it.
This is also where the first OWASP LLM risk surfaces: confidentiality. Sensitive information disclosure and training data poisoning both originate here, long before the model is ever deployed.
Layer 3 — Model Development
The ML Engineer takes the data scientist’s prototype and makes it production-worthy — proper testing, versioning, reproducibility, and feature engineering at scale. In LLM-based systems, the Prompt Engineer and AI Engineer have emerged as distinct specialists: designing prompts, building RAG pipelines, orchestrating agent workflows, and integrating with tools and APIs via frameworks like LangChain and LlamaIndex.
Integrity risks live here. Prompt injection, insecure output handling, and overreliance on model outputs are development-layer failures that no amount of monitoring can fully compensate for after the fact.
Layer 4 — Deployment and Operations
The MLOps Engineer owns the infrastructure that takes a model from a repository into production and keeps it healthy — CI/CD pipelines, Docker, Kubernetes, model registries, serving infrastructure on SageMaker or Vertex AI, and automated retraining when drift is detected. The DevOps and Platform Engineer provides the underlying compute, IAM controls, and networking. The SRE handles uptime and incident response at scale.
This is where availability risks materialise: model denial of service, excessive agency, and the slow degradation that happens when nobody is watching.
A model that worked on Tuesday can quietly fail by Sunday. MLOps is the reason it doesn’t.
Layer 5 — Governance and Assurance
The Responsible AI Specialist evaluates for bias, fairness, and explainability — increasingly non-negotiable in regulated industries. The ML Security Engineer protects against adversarial attacks, prompt injection, data poisoning, and model extraction. The QA and Model Validator designs evaluation suites specific to probabilistic ML behaviour, because traditional software testing does not catch the failure modes that matter here.
Governance is not a final checkpoint. It is a continuous audit that cuts across every layer above.
How the layers connect
This is not a linear handoff. It is a feedback loop. The AI Architect designs the system → Data Engineers build the pipelines → Data Scientists prototype → ML Engineers productionise → MLOps deploys and monitors → Ethics and Security audit throughout → the Product Manager closes the loop with user feedback → the cycle restarts. Each layer informs the next and corrects the previous.
The OWASP LLM Top 10 provides the governance lens for this entire loop: confidentiality risks at the data layer, integrity risks at model development, and availability risks at operations. Organisations that treat these as separate concerns end up with separate failures.
Why I care about this
This framework is not theoretical for me. Through the Johns Hopkins Applied Generative AI program — specifically the Secure and Responsible AI module — I have been building the governance and security layer into how I think about every system I design. The MIT Applied AI and Data Science program is adding the systems-level perspective: how models behave not in isolation, but inside complex, interconnected environments.
My years at AWS as a Cloud Engineer and dual SME for Amazon MQ and SQS gave me the infrastructure and integration layer from the inside — understanding how distributed messaging, access controls, and service reliability underpin everything that AI sits on top of. That is the context in which I now apply this pipeline thinking as an AI Solutions Consultant.
AI Engineers and specialists are not overhead. They are what stands between a promising pilot and a production system that actually holds.
Where have you seen this pipeline break down in your organisation? And which layer do you think is most consistently underinvested?
#GenerativeAI #AIEngineering #MLOps #ResponsibleAI #EnterpriseAI
Originally published on LinkedIn.